Seongho Jang
Ch.8 데이터 전처리(2): 데이터 병합 본문
3. 데이터 병합
bike_sub = bike.sample(n=4, random_state = 123)
bike_sub = bike_sub.reset_index(drop = True)
bike_sub = bike_sub.set_index("datetime")reset_index(drop = True)로 기존 index를 지우고,
set_index(df["datetime"])으로 datetime을 index로 설정하기
bike_1 = df.iloc[:3, :4]
bike_2 = df.iloc[5:8, :4]
pd.concat([bike_1, bike_2])concat: 데이터를 row 또는 column 방향으로 이어붙이는 함수
데이터 병합 시에 서로 다른 변수 속성 또는 인덱스에 주의

index가 다른데 그대로 이어붙이는 경우 이렇게 되므로,
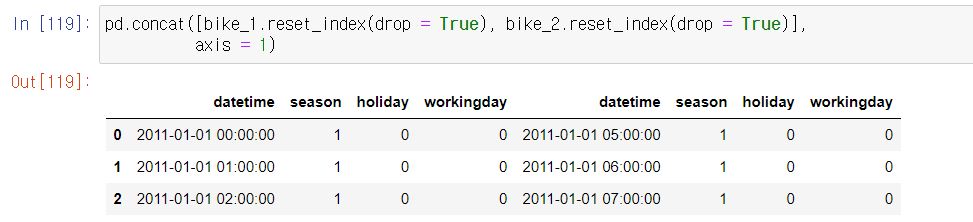
이렇게 reset_index를 해주기
df_A = pd.read_csv('join_data_group_members.csv')
df_B = pd.read_csv('join_data_member_room.csv')
pd.merge(left = df_A, right = df_B,
left_on = "member", right_on = "name",
how = "inner")merge: 문법이 상당히 직관적이다
문제2
여름과 겨울의 시간대별 registered 평균을 비교할 때 가장 차이가 많이 나는 시각은?
df = pd.read_csv('bike.csv')
df["datetime"] = pd.to_datetime(df["datetime"])
df["hour"] = df["datetime"].dt.hour
df_s2 = df.loc[df["season"] == 2, ]
df_s4 = df.loc[df["season"] == 4, ]
df_s2["registered2"] = df_s2["registered"]
df_s4["registered4"] = df_s4["registered"]
df_s2_reg = df_s2.groupby("hour")["registered2"].mean().reset_index(drop = True)
df_s4_reg = df_s4.groupby("hour")["registered4"].mean().reset_index(drop = True)
df_s2s4_reg = pd.concat([df_s2_reg, df_s4_reg], axis = 1)
df_s2s4_reg["diff"] = (df_s2s4_reg["registered2"] - df_s2s4_reg["registered4"]).abs()
df_s2s4_reg_max = df_s2s4_reg.loc[df_s2s4_reg["diff"] == df_s2s4_reg["diff"].max(), ]
df_s2s4_reg_max길다...
이것저것 조건이 많이 있을 때는, 필요한 부분만 발췌해서 다른 객체에 저장하고 연산하기
조건들만 헷갈리지 않는다면 패턴은 비슷해서 어렵지 않을 것 같다!
season == 2, season == 4 인 데이터의 registered라는 컬럼명이 같아서 바꿔줘야 했는데,
concat을 하고 나서
df_s2s4_reg.columns = ["hour", "reg2", "reg4"]와 같은 방법도 가능하니까 알아두기
문제3
비가 온 날에 30도가 넘는 시각의 count 평균은 얼마인가?
df = pd.read_csv('C:/Users/USER/Desktop/SH_Python/bike.csv')
bike["datetime"] = pd.to_datetime(df["datetime"])
bike["date"] = bike["datetime"].dt.date
bike_h100 = bike.groupby("date")["humidity"].max().reset_index()
# 각 일자별 humidity의 최대값 구하기
bike_h100 = bike_h100.loc[bike_h100["humidity"] == 100, ]
# 최대 humidity가 100인 날만 뽑아내기
bike_join = pd.merge(left = bike, right = bike_h100,
left_on = "date", right_on = "date", how = "inner")
# inner join으로 max humidity가 100인 날만의 데이터만 join
bike_join_up30 = bike_join.loc[bike_join["temp"] > 30, ]
bike_join_up30["count"].mean()간단한 문제에 비해서 생각보다 이것저것 손이 많이 간다...
데이터가 일자별/시간별 데이터가 있기 때문에,
groupby로 일자별 습도의 최대값을 구하고, 최대 습도가 100인 값만 발췌,
원본 데이터에 merge 한 다음 온도가 30도 넘는 데이터만 다시 발췌
생각보다 너무 복잡한 문제였다 ㅠ
'Data Science Lv.2' 카테고리의 다른 글
| Ch.14 다중 회귀분석 (0) | 2023.01.14 |
|---|---|
| Ch.9 - 10. 데이터 전처리(3) : 정렬, 변환, 사용자 정의함수 (0) | 2023.01.08 |
| Ch.6 - 7 데이터 전처리(1): 결측치, 이상치, 파생변수 생성 (0) | 2023.01.06 |
| Ch.18 의사결정나무 (0) | 2023.01.03 |
| Ch.17 KNN (0) | 2023.01.02 |
'Data Science Lv.2' Related Articles
more



