Seongho Jang
Ch.6 - 7 데이터 전처리(1): 결측치, 이상치, 파생변수 생성 본문
1. 결측치/이상치 처리
df.isna().sum()
df.isna().sum(axis = 1)axis = 0 : column 방향 (각 변수별 결측치 개수)
axis = 1 : row 방향 (각 row별 결측치 개수)
df.fillna(value = {"Sepal_Length" : df_na["Sepal_Length"].mean()})특정 column만 결측치를 수정하고 싶다면, value 뒤에 dictionary 형태로 작성하면 됨
그 외 다양한 method가 있는데 나중에 천천히 읽어보기...
value : scalar, dict, Series, or DataFrame
Value to use to fill holes (e.g. 0), alternately a dict/Series/DataFrame of values specifying which value to use for each index (for a Series) or column (for a DataFrame). Values in the dict/Series/DataFrame will not be filled. This value cannot be a list.
method : {'backfill', 'bfill', 'pad', 'ffill', None}, default None
Method to use for filling holes in reindexed Series pad /
ffill: propagate last valid observation forward to next valid
backfill / bfill: use next valid observation to fill gap.
df.dropna()결측치를 제거하는 메서드
axis : {0 or 'index', 1 or 'columns'}, default 0
Determine if rows or columns which contain missing values are removed.
* 0, or 'index' : Drop rows which contain missing values.
* 1, or 'columns' : Drop columns which contain missing value.
how : {'any', 'all'}, default 'any'
Determine if row or column is removed from DataFrame, when we have at least one NA or all NA.
문제 3
평균을 기반으로 1.5 표준편차를 넘어서는 값을 이상치라고 간주할 때, Sepal.Length 변수를 기준으로 이상치인 row 개수는 몇 개인가?
df = pd.read_csv('iris.csv')
sl_mean = df["Sepal.Length"].mean()
sl_std = df["Sepal.Length"].std()
cond_1 = df["Sepal.Length"] > (sl_mean + 1.5 * sl_std)
cond_2 = df["Sepal.Length"] < (sl_mean - 1.5 * sl_std)
df_out = df.loc[(cond_1) | (cond_2),]
len(df_out)평균+1.5시그마, 평균-1.5시그마를 각 객체에 저장하고, loc와 | (or) 연산자를 써서 코드를 작성
맨 마지막 두 줄 ( | 와 len)을 기억하기...
2. 파생변수 생성
파생변수 : 기존 변수를 조합하여 만들어내는 새로운 변수
df["is_setosa"] = np.where(df["Species"] == "setosa", 1, 0)
np.where(condition, x, y) : Return elements chosen from `x` or `y` depending on `condition`.
df = df.rename(columns = {"Sepal.Length" : "SL"})rename: 바꾸고자 하는 column명을 dictionary로 작성해주면 됨
df = pd.read_csv('bike.csv')
bike_sub= df.loc[:4, ["casual", "registered"]]
bike_sub.apply(func = sum, axis = 1)
bike_sub.apply(func = pd.Series.mean)
bike_sub.apply(func = lambda x : round(x.mean()))apply: dataframe에 이런저런 연산이 가능하게 하는 함수
sum, sqrt, square 등 다양한 함수에 적용 가능하며(단 mean은 X), lambda 함수를 사용할 수도 있다.
참고)
[Pandas] 16. apply 함수 사용법 알아보기.
안녕하세요~ 꽁냥이에요. 데이터 전처리를 하다 보면 특정 열을 변환해야 할 때가 있지요. 예를 들어 회귀 모형을 구축할 때 설명 변수를 log 함수를 이용하여 변환하는 것처럼 말이죠. Pandas에서
zephyrus1111.tistory.com
bike_sub["casual"] = bike_sub["casual"].astype(str)
bike_sub["casual"]+"대"astype : Dtype을 int / float / str으로 변환하는 메서드
Dtype이 int일 경우 뒤에 "대" 등을 붙이는 것이 안되므로 str로 바꾸고 편집해야 한다.
bike_time = pd.to_datetime(df["datetime"])
print(bike_time.dt.year)
print(bike_time.dt.month)
print(bike_time.dt.date)to_datetime : datetime 형식으로 바꾸는 메서드
year, month, day, hour, minute, second 등 거의 모든 시간과 관련된 메서드를 적용 가능하다.
bike_dum = pd.get_dummies(data = bike, columns = ["season"])
bike_dum.head(3)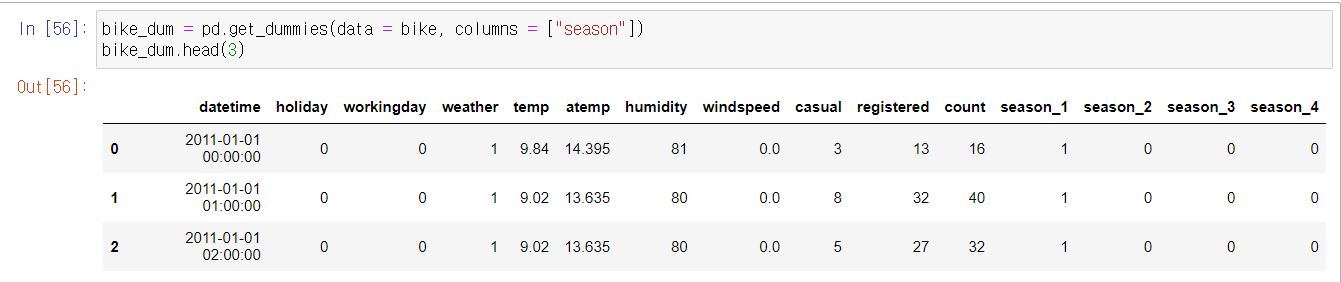
bike_dum = pd.get_dummies(data = bike, columns = ["season"], drop_first = True)
bike_dum.head(3)
get_dummies: One Hot Encoding을 위해 가변수를 생성하는 함수
drop_first = True를 지정하면 첫 가변수 제외 후 생성
관련 내용은 아래를 참고...
[pandas] pd.get_dummies() : 데이터전처리/가변수 만들기
[pandas] pd.get_dummies() : 가변수 만들기 머신러닝을 할 때 기계가 이해할 수 있도록 모든 데이터를 수치로 변환해주는 전처리 작업이 필수적이다. 예를들어, 숫자가 아닌 object형의 데이터들이 있다
devuna.tistory.com
문제3
시간대별 registered 평균을 산출했을 때 값이 가장 큰 시간은?
df = pd.read_csv('bike.csv')
df["datetime"] = pd.to_datetime(df["datetime"])
df["hour"] = df["datetime"].dt.hour
bike_hour = df.groupby("hour")["registered"].mean().reset_index()
bike_hour = bike_hour.loc[bike_hour["registered"] == bike_hour["registered"].max(), ]reset_index: 설정 인덱스를 제거하고 기본 인덱스(0,1,2, ... , n)으로 변경하는 메서드
편하게 이해하자면, array 형식에서 dataframe 형식으로 변환하기 위해 사용하였다.
bike_hour값을 출력하면 문제는 풀리지만, loc를 이용하여 최대값을 지정하는 방법도 꼭 알아두기
'Data Science Lv.2' 카테고리의 다른 글
| Ch.9 - 10. 데이터 전처리(3) : 정렬, 변환, 사용자 정의함수 (0) | 2023.01.08 |
|---|---|
| Ch.8 데이터 전처리(2): 데이터 병합 (0) | 2023.01.08 |
| Ch.18 의사결정나무 (0) | 2023.01.03 |
| Ch.17 KNN (0) | 2023.01.02 |
| Ch.15 로지스틱 회귀분석 (0) | 2023.01.02 |


